Excelを使った深層学習用教材
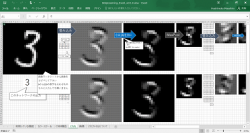
Excelのシートを利用したCNNの中間層の可視化を行っています。実際に入力画像を変更でき、途中にどのような処理を行っているかを確認することができます。
Google Colaboratory
一番短い深層学習プログラム(Keras ver.) Google Colaboratoryを開いて下さい.
rad.medアカウントをお持ちの方はこちらからサンプルプログラムが参照できます.
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from keras.utils import np_utils
(img,n),(img_test , n_test ) = mnist.load_data()
img = img.reshape( 60000, 28, 28, 1 )
img_test = img_test.reshape( 10000, 28, 28, 1 )
n = np_utils.to_categorical( n )
n_test = np_utils.to_categorical( n_test )
model = Sequential( )
model.add( Conv2D(32,kernel_size=(3,3),activation='relu',input_shape=(28,28,1)))
model.add( MaxPooling2D( pool_size = ( 2, 2 )))
model.add( Conv2D( 64 , kernel_size = ( 3, 3 ), activation = 'relu'))
model.add( MaxPooling2D( pool_size = ( 2, 2 )))
model.add( Flatten( ))
model.add( Dense( 128 , activation = 'relu'))
model.add( Dropout( 0.5 ))
model.add( Dense( 10 , activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy' , optimizer = 'adam' , metrics=['accuracy'])
model.fit( img , n , batch_size = 200 , epochs=3 )
score = model.evaluate( img_test , n_test )
print('accuracy : ', score[1] )
解説
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from keras.utils import np_utils
ライブラリを利用するための宣言。Google Colaboratoryに標準でインストールされているKerasを用います。
(img,n),(img_test , n_test ) = mnist.load_data()
データをダウンロードし、メモリに読み込みます。
MNISTという28×28ピクセルの手書き文字画像データセットを用います。
Pythonでは
(a , b) , (c , d) = (5 , 7) , (4 , 3)
のように複数の戻り値(タプル)を複数の変数で受け取ることができます。
下記のコードで画像の中身を確認できます。
from keras.datasets import mnist
from matplotlib import pyplot as plt
from matplotlib import cm
(img,n),(img_test , n_test ) = mnist.load_data()
plt.axis('off')
plt.imshow(img[0], cmap=cm.gray)
plt.show()
img = img.reshape(60000, 28, 28, 1)
img_test = img_test.reshape(10000, 28, 28, 1)
CNNに入力するために1チャンネルの画像の形式に変換します。
n = np_utils.to_categorical(n)
n_test = np_utils.to_categorical(n_test)
正解データをカテゴリーデータに変換します。
例) 3 → [0,0,0,1,0,0,0,0,0]
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu',input_shape=(28,28,1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
ニューラルネットのモデル部分。
model.summary()
で詳細が表示されます。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(img, n, batch_size=200, epochs=3)
モデルの計算準備と学習部分。
batch_sizeは1回に計算する画像数、epochsは全画像を何周学習するかというパラメータ。
score = model.evaluate(img_test, n_test)
print('accuracy : ', score[1])
検証と検証結果の表示。